释题:循序渐进。想象一下一本 500 页的手册,通过目录页、章节、附录三层结构,我们可以把 token 利用率提升 98%。—— 这就是循序渐进的内涵。本节中隐藏了三个神秘关键词:目录、路由和契约。你可以在阅读中,自己寻找并体会这三个关键词的内涵。
你好,我是黄佳。
前两讲我们学习了 SKILL.md 的基本结构(第 9 讲)和任务型 Skills 的设计方法(第 10 讲),也理解了 Skills 在 Agent 生态中的核心定位——可操作知识。但真实场景中,专业能力往往很复杂,比如一个财务分析 Skill,它需要包含财务指标计算公式、不同行业的基准数据、各种报表模板、分析脚本以及案例示例。
如果把这些全部塞进一个 SKILL.md,会有两个问题。
Token 爆炸:每次激活都要加载几千 tokens。
信息噪声:用户问“收入增长率怎么算”,Claude 却要阅读关于成本分析、现金流、资产负债表的全部内容。
渐进式披露(Progressive Disclosure,也即是渐进式的加载啦) 就是解决这个问题的架构模式。但渐进式披露的意义远不止节省 token。从企业本体论的视角看,它是知识管理(Knowledge Management)在 AI 架构中的技术映射——如何让正确的知识在正确的时刻到达正确的执行者手中。
这一课干货内容极多,思考题也多,请大家做好头脑被新知识冲击的准备。我们开始了。
渐进式披露的设计哲学
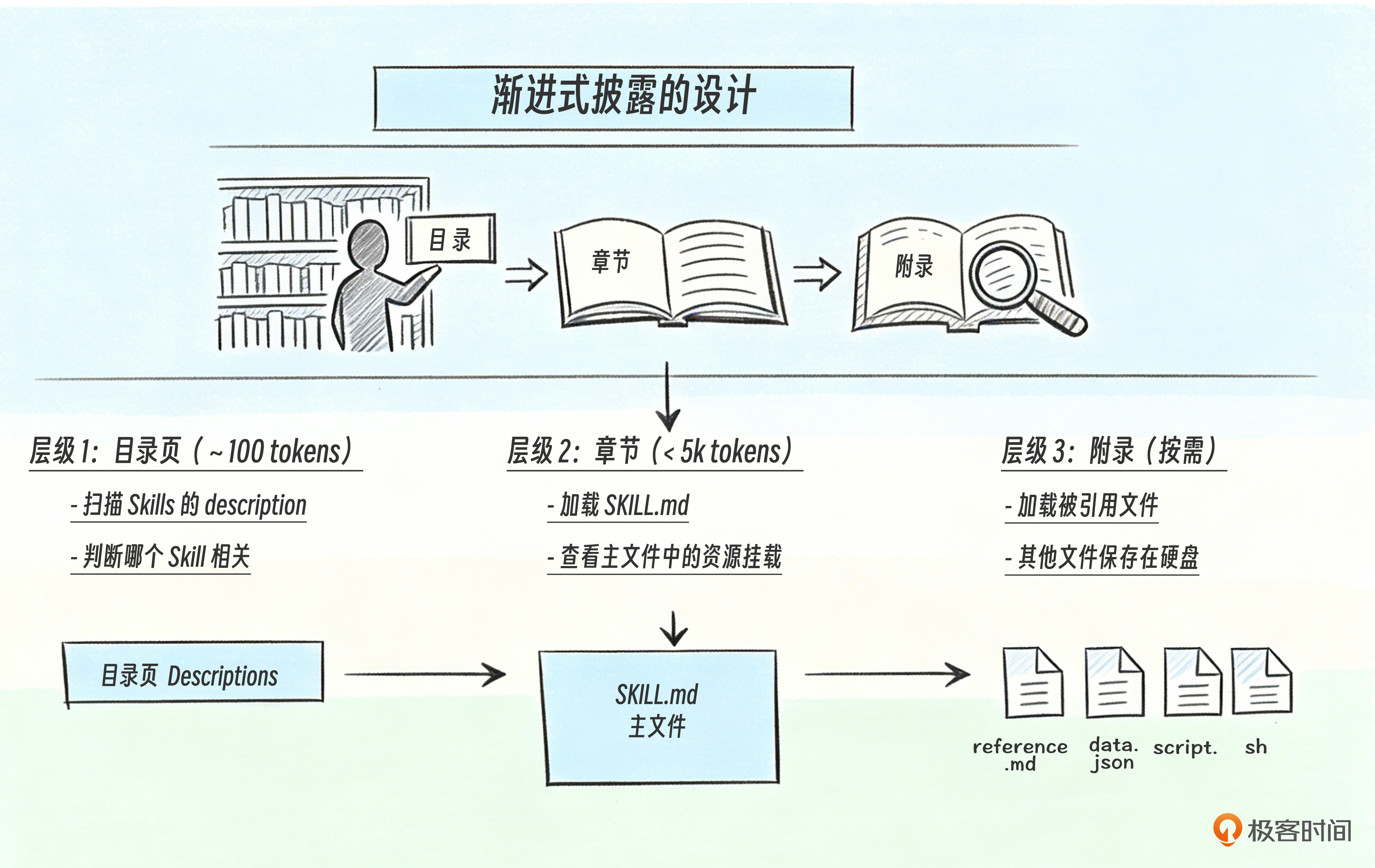
让我们用图书馆来类比渐进式披露的设计哲学。走进一个图书馆找资料时,你不会一次把所有书都读一遍。你是先看目录找到相关分类,再选一本具体的书,最后翻到需要的章节深入阅读。信息是逐层展开的,而不是一次性全部载入大脑。
Skill 的渐进式披露设计也是一样:第一层只扫描 description 作为“目录”,第二层在触发时加载 SKILL.md 主文件作为“章节”,第三层再按需加载被引用的具体文件作为“附录”。结构化分层替代信息堆叠,让系统在规模变大时依然高效、可控。
认知经济学:上下文窗口是稀缺资源
在讨论 token 节省之前,让我们建立一个更深层的认知框架。
上下文窗口是 LLM 的“工作记忆”。 人类的工作记忆大约能同时处理 7±2 个信息块(Miller’s Law)。LLM 的上下文窗口虽然大得多(200K tokens),但它也是有限的稀缺资源,而且有一个更严重的问题——注意力稀释效应。

这就是渐进式披露的经济学基础:
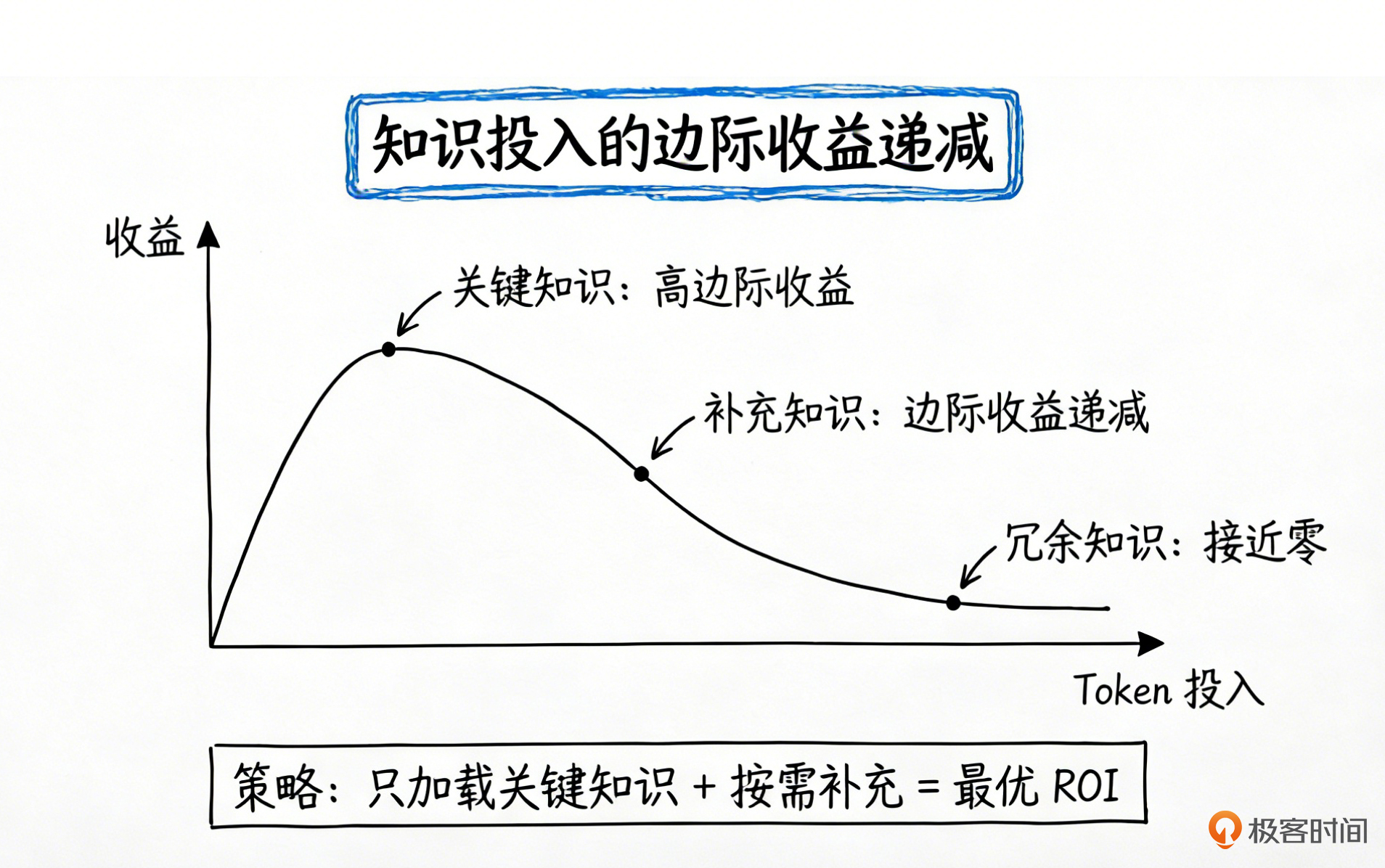
渐进式披露的本质:以最小的 token 投入获得最高的任务完成质量——这就是知识的投资回报率(Knowledge ROI)。

Token 节省效果方面。让我们用数字说话。假设一个复杂的 Skill 是这样的:
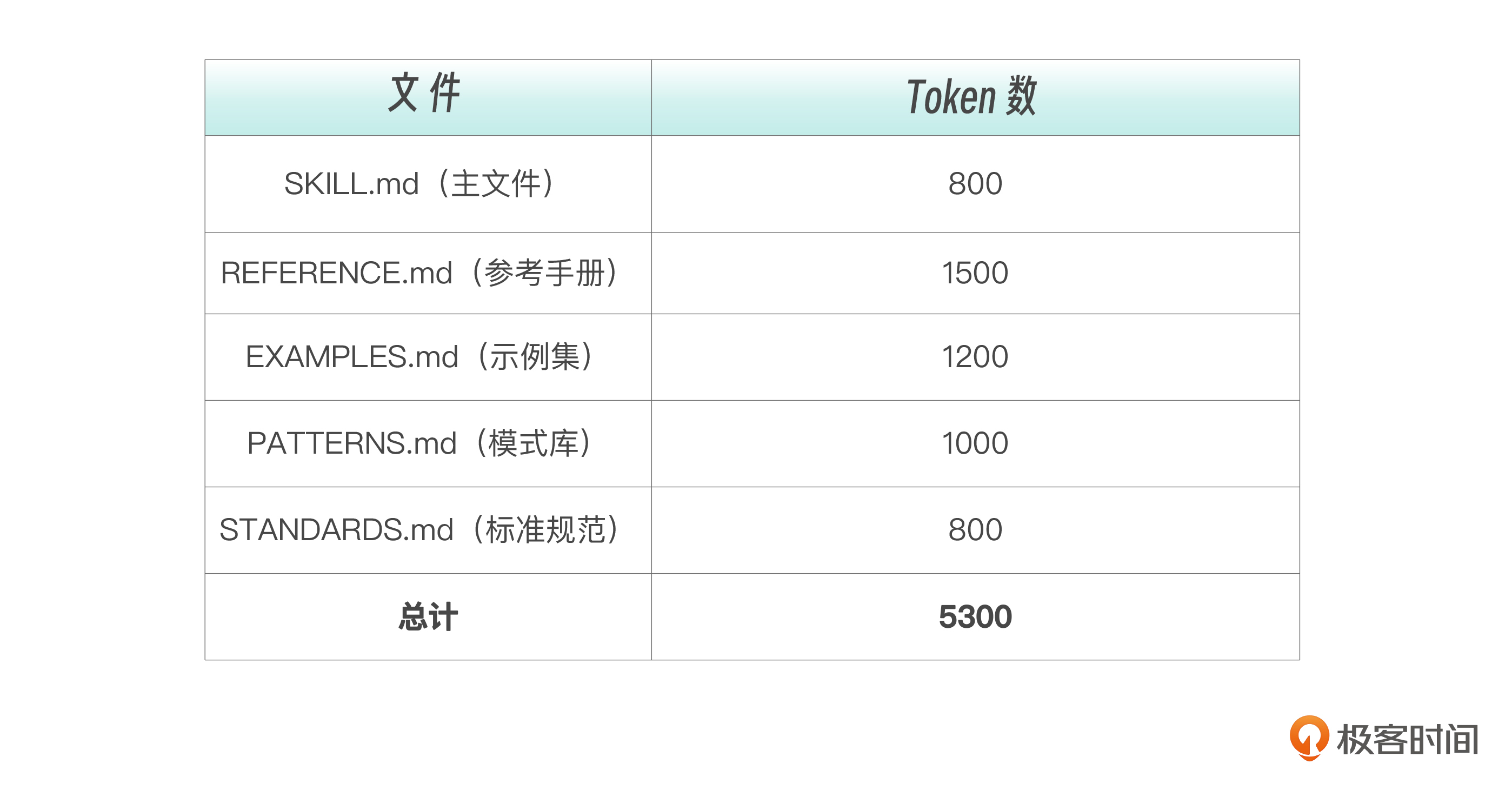
不同场景下的 Token 消耗(大概估算哈)。
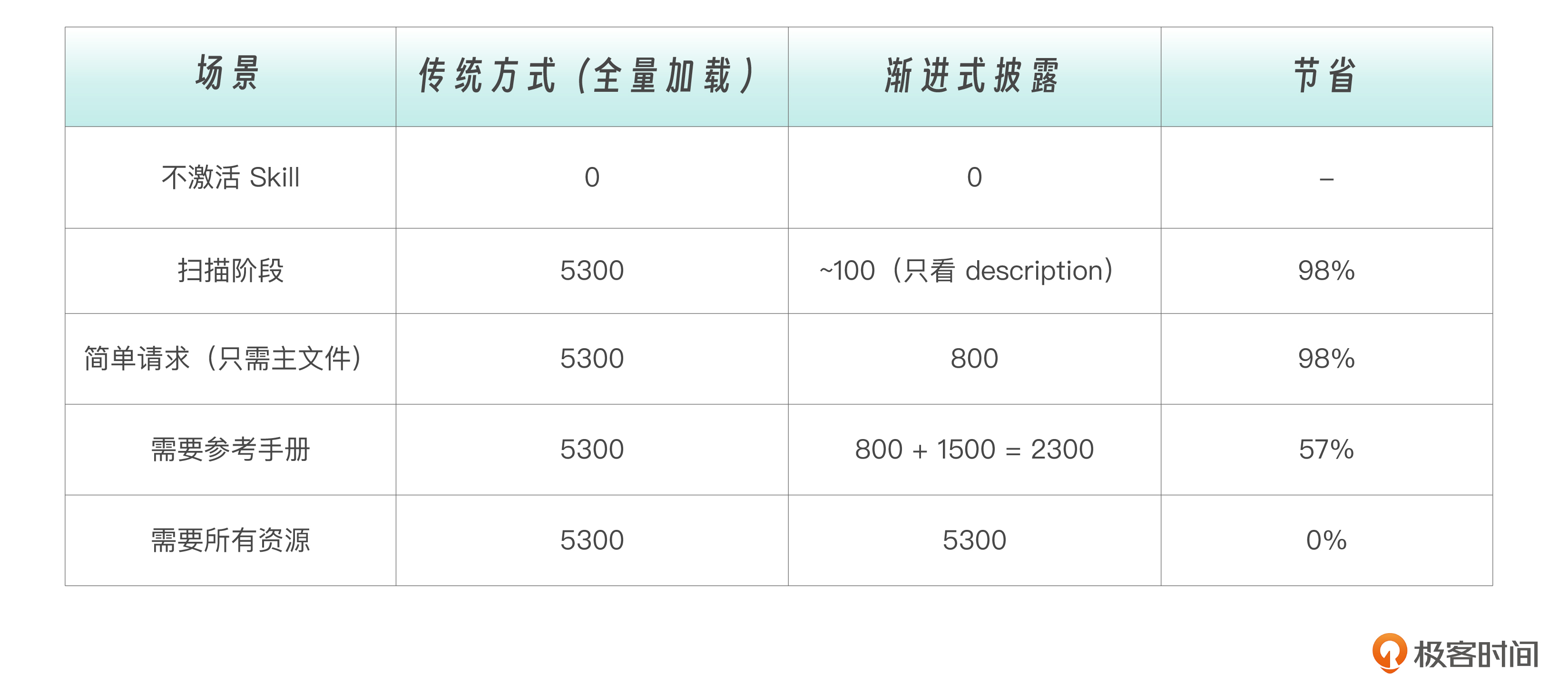
不难发现,大多数请求只需要部分资源,渐进式披露在这些场景下大幅节省 tokens。
财务分析 Skill:三层架构详解
我们今天要设计的这个财务分析 Skill,本质上是一个结构化的财务能力包:当用户提出与收入、成本、利润、增长率、毛利率、ROE/ROA 或整体财务表现相关的问题时,它会被激活,先在主文件中完成问题识别和分析路径判断,再按需加载对应的公式说明、行业基准数据或报告模板,必要时调用脚本进行确定性计算,最后输出结构清晰、口径一致的分析结果。
它的目标不是给投资建议,而是在明确数据前提下,提供可复现、可解释、可结构化的财务分析支持,用最少的上下文投入完成高质量的专业判断。
下面来看看这个Skill的三层渐进式的架构设计,我们用看书时经常采用的目录、章节、附录来对渐进式架构做类比。
层级 1:目录页(Entry Point)
这是 Skills 系统扫描阶段读取的内容——只有 description。
name: financial-analyzing description: Analyze financial data, calculate ratios, and generate reports. Use when the user asks about revenue, costs, profits, margins, financial metrics, or needs financial analysis.
目录页的设计原则是,description 足够丰富,让 Claude 能准确判断相关性。但不要太长,因为所有 Skill 的 description 共享 15,000 字符的总预算。如果 Skill 数量多导致 description 被截断,可以通过 SLASH_COMMAND_TOOL_CHAR_BUDGET 环境变量调整。

层级 2:章节(Main Content)
章节指的是SKILL.md 的正文部分——激活后才加载。
Financial Analysis Skill
Quick Start
基础的财务分析流程...
Available Analyses
Revenue Analysis
For detailed formulas, see reference/revenue.md
Cost Analysis
For detailed formulas, see reference/costs.md
Profitability Analysis
For detailed formulas, see reference/profitability.md
When to Load Additional Resources
- 需要具体公式 → 加载对应的 reference/*.md
- 需要行业基准 → 加载 data/benchmarks.json
- 需要报告模板 → 加载 templates/*.md
这一部分的设计原则是主文件提供“路线图”,通过文件引用指向详细内容,然后Claude 根据用户请求决定加载哪些具体内容。
层级 3:附录(On-Demand Resources)
只有当 SKILL.md 中引用了这些文件,Claude 才会去读取这一类文件。
.claude/skills/financial-analyzing/ # 标准 Skill 目录 ├── SKILL.md # 主文件(总是加载) ├── reference/ # 参考资料 │ ├── revenue.md # 收入分析公式 │ ├── costs.md # 成本分析公式 │ └── profitability.md # 盈利分析公式 ├── templates/ # 报告模板 │ ├── quarterly_report.md │ └── annual_report.md ├── data/ # 数据文件 │ └── industry_benchmarks.json └── scripts/ # 分析脚本 ├── calculate_ratios.py └── generate_report.sh
这一部分内容的设计原则是文件名要有描述性(revenue.md 而非 ref1.md)——Claude 根据文件名判断是否需要加载。
所有辅助文件都在 Skill 自己的目录内,随 Skill 一起分发。相关内容放在一起,并按功能域组织子目录。例如脚本有自己独立存放的目录,Claude 可以执行它,但不需要去“理解”(这样也就节省了Token)。
财务分析 Skill:项目设计细节
下面我们还原这个财务分析Skill的构建细节,从零构建一个完整的财务分析 Skill。
这个Skill标准部署结构如下:
your-project/.claude/skills/financial-analyzing/ ├── SKILL.md # 主 Skill 文件 ├── reference/ │ ├── revenue.md # 收入分析 │ ├── costs.md # 成本分析 │ └── profitability.md # 盈利分析 ├── templates/ │ └── analysis_report.md # 分析报告模板 └── scripts/ └── calculate_ratios.py # 比率计算脚本
课程示例文件在 .claude/skills/financial-analyzing/ 中。
主文件SKILL.md设计如下。
name: financial-analyzing description: Analyze financial data, calculate financial ratios, and generate analysis reports. Use when the user asks about revenue, costs, profits, margins, ROI, financial metrics, or needs financial analysis of a company or project. allowed-tools: - Read - Grep - Glob - Bash(python:*)
Financial Analysis Skill
You are a financial analyst. Help users analyze financial data, calculate key metrics, and generate insightful reports.
Quick Reference
| Analysis Type | When to Use | Reference |
|---|---|---|
| Revenue Analysis | 收入、营收、销售额相关 | reference/revenue.md |
| Cost Analysis | 成本、费用、支出相关 | reference/costs.md |
| Profitability | 利润、毛利率、净利率相关 | reference/profitability.md |
Analysis Process
Step 1: Understand the Question
- What financial aspect is the user asking about?
- What data do they have available?
- What format do they need the answer in?
Step 2: Gather Data
- Request necessary financial data from user
- Or read from provided files/sources
Step 3: Calculate Metrics
For specific formulas and calculations:
- Revenue metrics → see reference/revenue.md
- Cost metrics → see reference/costs.md
- Profitability metrics → see reference/profitability.md
To run calculations programmatically:
python scripts/calculate_ratios.py <data_file>
### Step 4: Generate Report
Use the template in `templates/analysis_report.md` for structured output.
## Output Guidelines
1. Always show your calculations
2. Explain what each metric means
3. Provide context (industry benchmarks when available)
4. Give actionable recommendations
## Important Notes
- Never make up financial data
- Ask for clarification if data is incomplete
- Flag any unusual numbers that might be errors
这个Skill包括一个Quick Reference 表格,让 Claude 快速定位需要哪个参考文件。使用相对路径指向资源,进行清晰的文件引用,并通过脚本调用说明告诉 Claude 如何使用计算脚本。同时只允许 Read、Grep、Glob 和特定的 Bash 命令。
仔细观察上面的 SKILL.md 设计,你会发现它本质上是一个路由器——根据用户请求的类型,将 Claude 导向不同的资源文件:
用户请求 → SKILL.md(路由判断) → 目标资源
│
├─ "收入相关" → reference/revenue.md
├─ "成本相关" → reference/costs.md
├─ "利润相关" → reference/profitability.md
├─ "要报告" → templates/analysis_report.md
└─ "要计算" → scripts/calculate_ratios.py
这个路由的关键设计技巧是 Quick Reference 表格。它用最少的 token(3 行表格 ≈ 50 tokens)告诉 Claude 五个方向的路由。如果没有这个表格,Claude 需要阅读整个 SKILL.md 的 Step 3 才能知道“收入问题去找 revenue.md”——这就是信息密度的差异。
写好路由表格的经验法则包括。
用“用户可能说的关键词”作为路由条件(而非“文件内容的技术名称”)
每个路由条目一行,不要超过 10 个条目(超过就需要分层)
高频路由放前面
除主文件之外,这个Skill中还包括下面几个参考文件,也就是附录。
参考文件:reference/revenue.md
这是渐进式披露的层级 3 资源——只有当用户问到收入相关问题时,Claude 才会根据 SKILL.md 中 Quick Reference 表格的路由指引加载这个文件。它包含收入增长率、同比/环比、ARPU 等核心公式和异常信号判断标准。
# Revenue Analysis Reference
## Key Metrics
### Revenue Growth Rate
**Interpretation:**
- > 20%: High growth
- 10-20%: Moderate growth
- < 10%: Low growth
- < 0%: Declining
### Year-over-Year (YoY) Growth
## Red Flags to Watch
1. **Revenue concentration** > 30% from single customer
2. **Declining growth rate** over 3+ consecutive quarters
3. **Large discrepancy** between booked and recognized revenue
4. **Unusual seasonality** patterns
参考文件:reference/profitability.md
这是与 revenue.md 平级的另一个按需加载文件,聚焦盈利能力分析。包含毛利率、营业利润率、净利率三大 Margin 指标,以及 ROI、ROA、ROE 三大 Return 指标,并附带行业基准数据供对比参考。
# Profitability Analysis Reference
## Margin Metrics
### Gross Profit Margin
**Industry Benchmarks:**
| Industry | Typical Range |
|----------|--------------|
| Software/SaaS | 70-85% |
| Retail | 20-50% |
| Manufacturing | 25-35% |
| Services | 50-70% |
### Operating Profit Margin
Operating Income = Revenue - COGS - Operating Expenses
Net Margin = Net Income / Revenue × 100%Net Income = Revenue - All Expenses - Taxes
ROI = (Gain from Investment - Cost of Investment) / Cost of Investment × 100% ROA = Net Income / Total Assets × 100% ROE = Net Income / Shareholders' Equity × 100% ```Profitability Red Flags
- Gross margin declining while revenue grows (pricing pressure)
- Operating margin < 0 (not operationally profitable)
- ROE significantly higher than ROA (high leverage risk)
- Net margin < industry average for 3+ years
报告模板:templates/analysis_report.md 模板文件是渐进式披露中的特殊资源——它不提供“知识”,而是提供“输出格式”。当用户要求“生成分析报告”时,Claude 加载这个模板来确保输出结构统一、专业。这就是企业知识管理中“标准化输出”的技术映射。
Financial Analysis Report Template
Executive Summary
[One paragraph summarizing key findings and recommendations]
Company/Project Overview
- Name: [Entity name]
- Period Analyzed: [Date range]
- Data Sources: [Where data came from]
Key Metrics
| Metric | Value | Industry Avg | Assessment |
|---|---|---|---|
| Revenue Growth | X% | Y% | Above/Below |
| Gross Margin | X% | Y% | Above/Below |
| Net Margin | X% | Y% | Above/Below |
| ROI | X% | Y% | Above/Below |
Detailed Analysis
Revenue Analysis
[Findings about revenue trends, composition, growth]
Cost Analysis
[Findings about cost structure, efficiency]
Profitability Analysis
[Findings about margins, returns]
Trend Analysis
[How metrics have changed over time]
Recommendations
Immediate Actions
- [High priority recommendation]
- [High priority recommendation]
Medium-term Improvements
- [Medium priority recommendation]
Long-term Strategy
- [Strategic recommendation]
Risk Factors
- [Key risk 1]
- [Key risk 2]
Appendix
[Supporting calculations, data tables, charts]
计算脚本:scripts/calculate_ratios.py 脚本是 Skills 与 Tools 的桥梁——它把“知识”(公式)变成了“行动”(代码)。Claude 不需要理解计算逻辑,只需执行 python calculate_ratios.py data.json 即可获得准确结果。这比让 LLM 自己做数学运算更可靠、更省 token。
!/usr/bin/env python3
""" Financial Ratios Calculator
Usage:
python calculate_ratios.py
Data file format (JSON): { "revenue": 1000000, "cogs": 400000, "operating_expenses": 300000, "net_income": 150000, "total_assets": 2000000, "shareholders_equity": 800000, "previous_revenue": 900000 } """
import json import sys
def calculate_ratios(data): """Calculate common financial ratios.""" ratios = {}
# Revenue Growth
if 'previous_revenue' in data and data['previous_revenue'] > 0:
ratios['revenue_growth'] = (
(data['revenue'] - data['previous_revenue'])
/ data['previous_revenue'] * 100
)
# Gross Margin
if 'cogs' in data:
gross_profit = data['revenue'] - data['cogs']
ratios['gross_margin'] = gross_profit / data['revenue'] * 100
# Operating Margin
if 'cogs' in data and 'operating_expenses' in data:
operating_income = data['revenue'] - data['cogs'] - data['operating_expenses']
ratios['operating_margin'] = operating_income / data['revenue'] * 100
# Net Margin
if 'net_income' in data:
ratios['net_margin'] = data['net_income'] / data['revenue'] * 100
# ROA
if 'net_income' in data and 'total_assets' in data:
ratios['roa'] = data['net_income'] / data['total_assets'] * 100
# ROE
if 'net_income' in data and 'shareholders_equity' in data:
ratios['roe'] = data['net_income'] / data['shareholders_equity'] * 100
return ratios
def main():
if len(sys.argv) < 2:
print("Usage: python calculate_ratios.py
with open(sys.argv[1], 'r') as f:
data = json.load(f)
ratios = calculate_ratios(data)
print("\n=== Financial Ratios ===\n")
for name, value in ratios.items():
print(f"{name.replace('_', ' ').title()}: {value:.2f}%")
if name == 'main': main()
上述这些参考文件、脚本会按需进行引用。
渐进式加载实战演示
让我们看看用户不同请求时,Skill 是如何渐进式加载的。
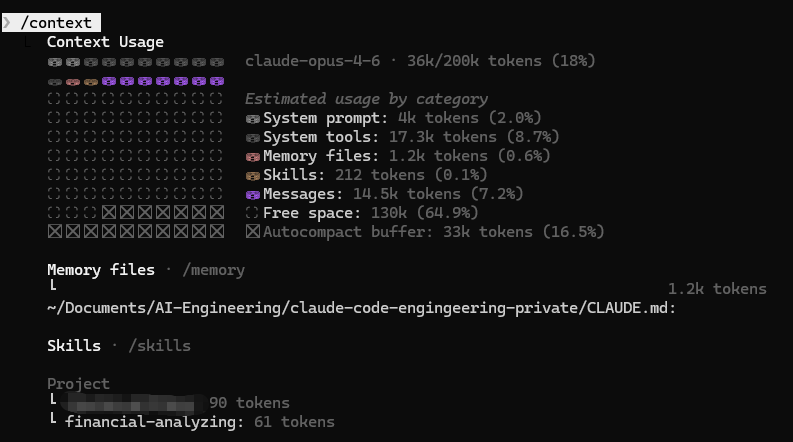
首先,先介绍一个技巧,在会话内部,你可以通过/context 命令来查看当前所消耗的Token和上下文内存的具体情况。
下面我们再来比较不同的渐进式加载情景。
场景 1:简单问题
用户:毛利率怎么计算?
Claude 加载过程:
扫描 Skills → 发现 financial-analyzing 匹配
加载 SKILL.md → 看到 “Profitability → see reference/profitability.md”
加载 reference/profitability.md → 找到毛利率公式
回答用户
Token 消耗:~100(扫描)+ 800(主文件)+ 600(profitability.md 部分)= ~1500 tokens
其他文件(revenue.md、costs.md、templates、scripts)完全没有加载。

如图所示,此时,Claude只读取了 .claude/skills/financial-analyzing/reference/profitability.md这一个文件的83行。

场景 2:完整分析
用户:帮我分析data目录中的财务数据,生成一份完整的分析报告。
Claude 加载过程:
扫描 Skills,发现 financial-analyzing 匹配
加载 SKILL.md
分析任务需要,加载所有 reference/*.md
需要报告格式,加载 templates/analysis_report.md
需要计算 ,执行 scripts/calculate_ratios.py
Token 消耗:全部资源都用到了。

两个场景的关键对比如下。
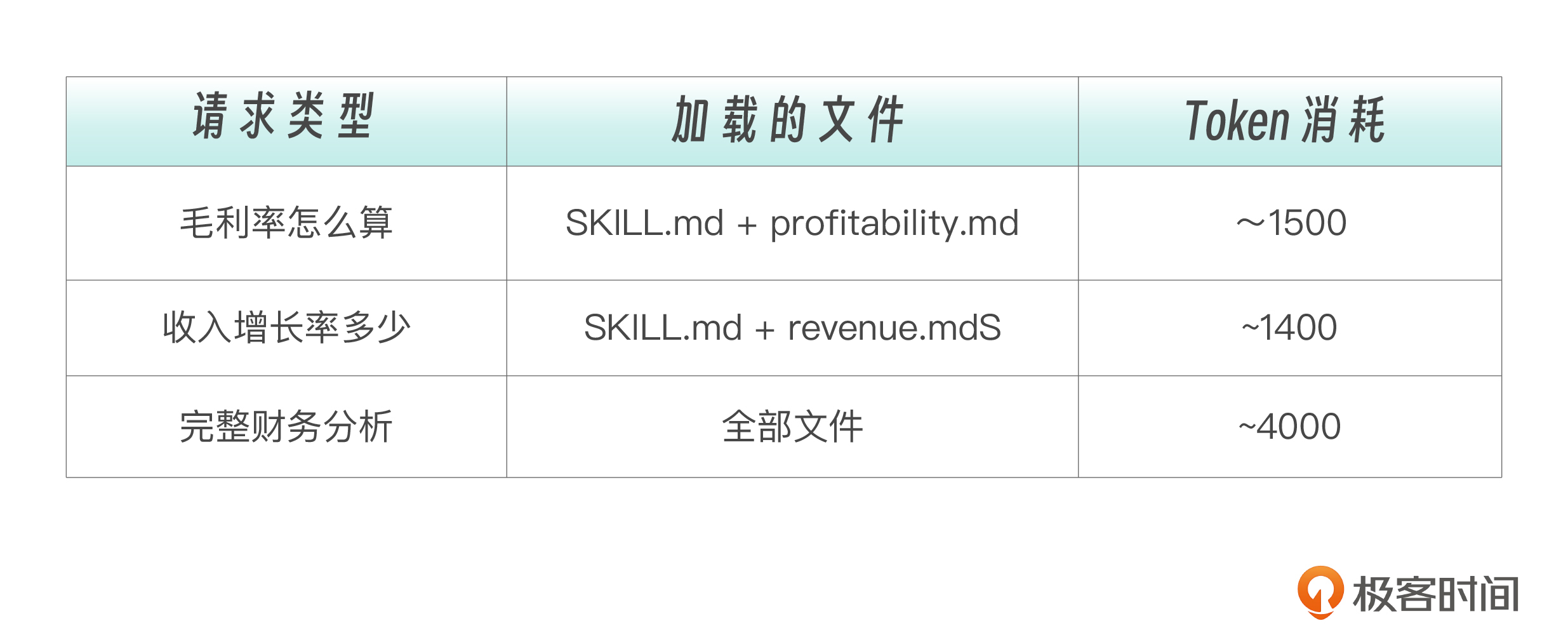
由此我们可以看出渐进式披露的价值:大部分请求只需要部分资源,平均节省 50-80% tokens。
渐进式的设计模式与最佳实践
首先谈文件组织模式,有按功能分类和按使用频率分类两种。如果你的 Skill 有多种类型的资源(知识+模板+脚本),用功能分类;如果只有不同深度的知识文档,用频率分类。
按功能分类(推荐):
.claude/skills/my-skill/ ├── SKILL.md # 入口 + 路由(< 500 行) ├── reference/ # 知识库(公式、规范、基准) ├── templates/ # 输出模板(报告、代码骨架) ├── examples/ # 示例集(输入输出样本) ├── scripts/ # 可执行脚本(计算、生成、验证) └── data/ # 静态数据(JSON、CSV)
按使用频率分类(适合知识型 Skill):
.claude/skills/my-skill/ ├── SKILL.md # 核心内容(高频,总是加载) ├── QUICKREF.md # 快速参考(高频,常被加载) ├── DETAILED.md # 详细说明(中频,按需加载) └── ADVANCED.md # 高级用法(低频,很少加载)
其次是主文件设计原则。主文件应该控制在 500 行以内(官方建议:Keep SKILL.md under 500 lines. Move detailed reference material to separate files.)。然后应该提供路线图,用 Quick Reference 表格做个快速路由,而非让 Claude 逐行扫描。
什么内容放主文件,什么内容放引用文件?答案是高频内容内联,低频内容外链。最常用的信息直接放在主文件(80/20 法则——80% 请求只需 20% 内容);偶尔用到的详细信息放在引用文件,用契约式引用。
此时终于说到本文第三个神秘关键字了。到底啥是契约式引用? SKILL.md 引用辅助文件时,不要只写一个路径——要写一个契约,让 Claude 知道什么时候该加载、加载后能得到什么:
❌ 弱引用(Claude 不知道何时该加载)
See reference/revenue.md for more details.
✅ 契约式引用(Claude 清楚加载条件和预期内容)
Revenue Analysis
When the user asks about revenue growth, ARPU, or revenue composition:
→ Load reference/revenue.md for calculation formulas and industry benchmarks
契约式引用三要素包括:
触发条件:什么情况下应该加载(“当用户问到 X 时”)
文件路径:去哪里找
内容预期:加载后能得到什么(“计算公式和行业基准”)
这和第 6 讲子代理流水线中的“交接契约”是同一个工程思想:下游消费者需要知道上游提供什么,而不只是知道上游在哪里。
引用文件命名也有所讲究,要清晰,切忌模糊,重复。
好的命名
reference/revenue.md # 清晰表明内容 reference/profitability.md # 清晰表明内容 templates/quarterly_report.md # 清晰表明用途
差的命名
reference/ref1.md # 不知道是什么 docs/misc.md # 太模糊 file.md # 毫无信息
脚本适合封装复杂但确定性的逻辑。脚本的好处是 Claude Code可以直接执行它,而不需要“理解”"每一行代码,因此可以减少 Token 消耗(不需要把逻辑放在 prompt 中),便于测试和维护(独立的代码文件)。
适合脚本
- 财务比率计算(公式固定)
- 数据格式转换(规则明确)
- 文件批量处理(重复性高)
不适合脚本
- 开放性分析(需要判断)
- 创意性任务(需要灵活性)
- 交互式决策(需要反馈)
脚本不仅能做计算,还能生成可视化结果。Claude官方提供了一种强大的模式:Skill 中的脚本生成交互式 HTML 文件,在浏览器中打开。
用户请求 → Skill 激活 → Claude 执行脚本 → 生成 HTML → 浏览器打开
下面是一个代码库可视化 Skill的示例。
.claude/skills/codebase-visualizer/ ├── SKILL.md # 指令:调用 visualize.py └── scripts/ └── visualize.py # 生成交互式目录树 HTML
SKILL.md 只需要告诉 Claude 运行脚本:
name: codebase-visualizer description: Generate an interactive tree visualization of your codebase. Use when exploring a new repo or understanding project structure. allowed-tools: Bash(python *)
Run the visualization script from your project root:
```bash python ~/.claude/skills/codebase-visualizer/scripts/visualize.py . ```
This creates codebase-map.html and opens it in your default browser.
这个示例的工程价值在于,Claude 不需要理解 HTML/CSS/JS 的实现细节(节省 token),脚本用 Python 标准库即可,无需安装额外依赖。同样的模式还能用于依赖关系图、测试覆盖率报告、API 文档、数据库 schema 可视化。
这体现了渐进式披露的极致——Claude 只需要知道“运行什么命令”(10 tokens),而非“如何生成 HTML”(2000+ tokens)。
内容拆分的工程方法论
学完了架构和实战,我们来解决一个更根本的问题:面对一坨知识,怎么决定什么放 SKILL.md、什么放引用文件、什么放脚本?
请看下面的知识拆分决策树。
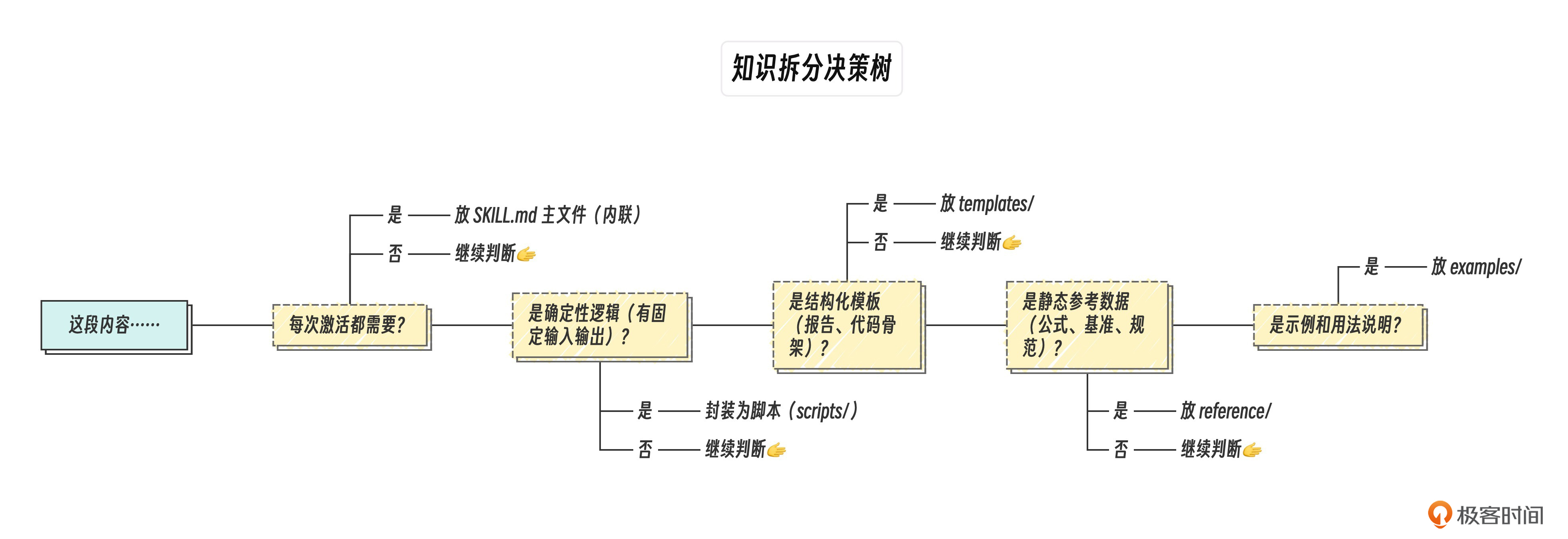
这棵树背后真正体现的,是核心语义内联,确定逻辑外包,结构独立,数据延迟,示例分离等大原则。
当你按照这个思路拆分 Skill,你构建的就不再是一份长文档,而是一套有层级的能力结构。这也是渐进式加载能够真正发挥作用的前提。
官方建议 SKILL.md 控制在 500 行以内。为什么是 500 行?
500 行 ≈ 2000-3000 tokens,是一个 Skill 激活后的合理上下文开销。
加上 Claude 自身的系统提示和对话上下文,总 token 数保持在可控范围。
超过 500 行意味着你可能把“参考资料”混进了“路由指令”。
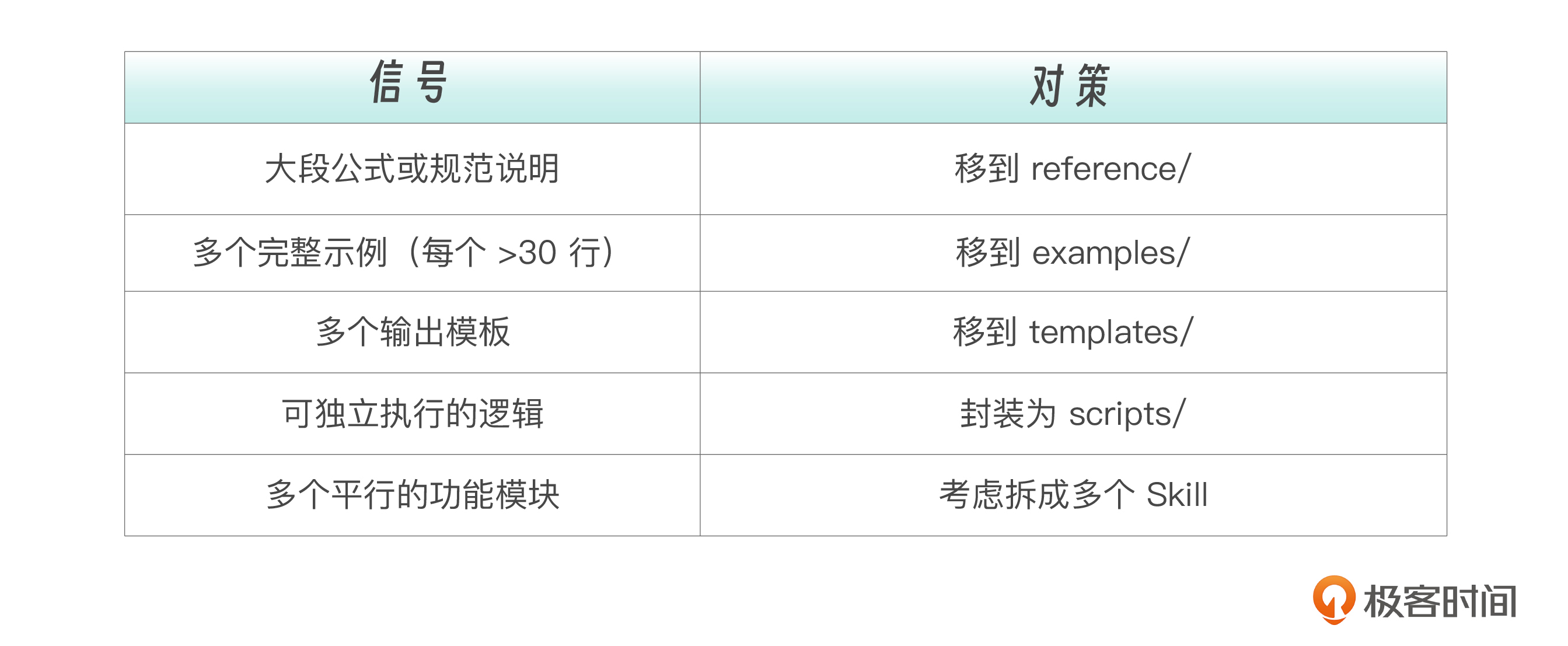
超过 500 行时的重构信号和对策如下:
拆分决策树和目录结构不是随意设计的——它们映射到企业知识管理的经典范式。
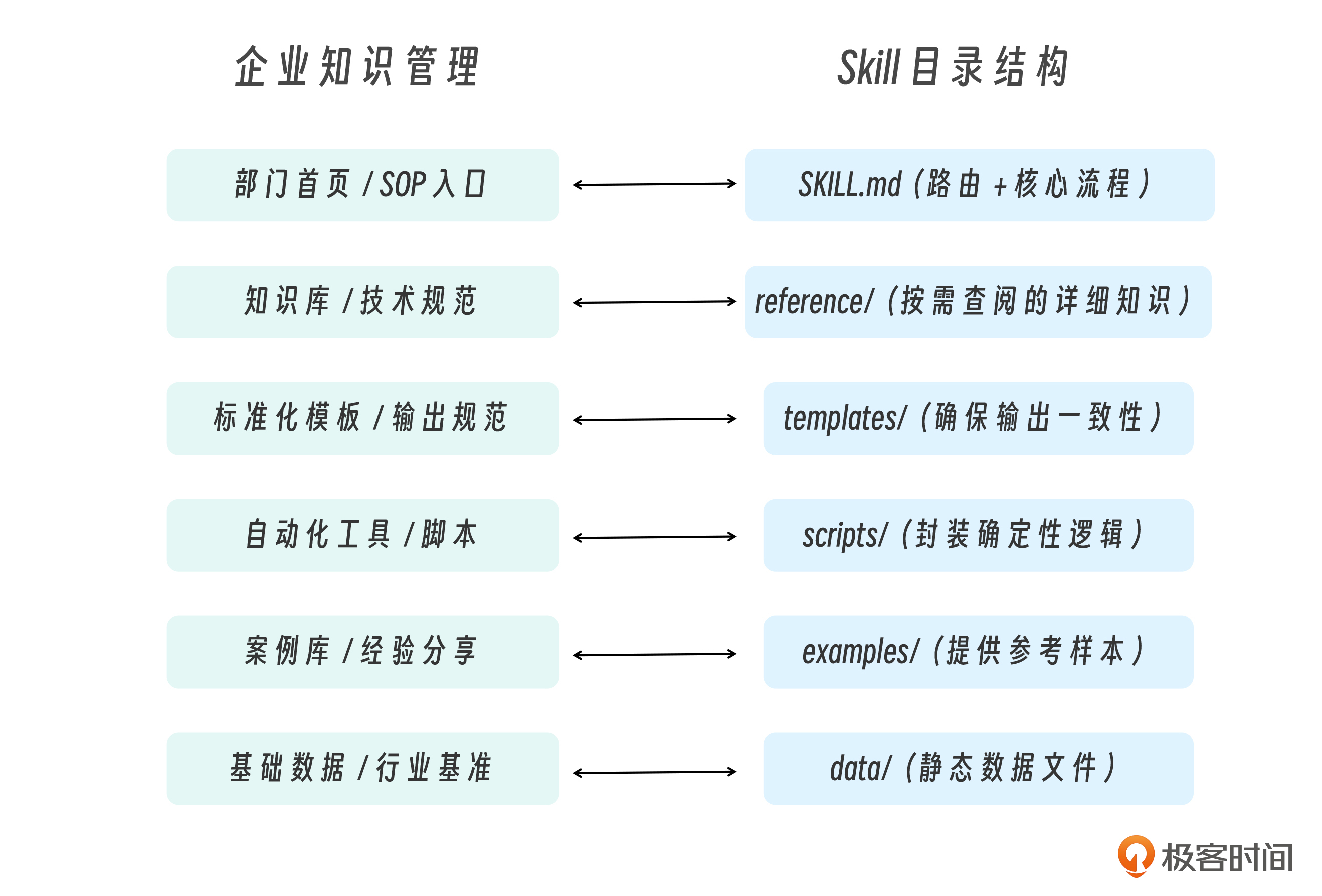
想想看,上面这个映射的工程启示有哪些?
SKILL.md = 部门 SOP 首页。好的 SOP 首页不会把所有操作细节都列出来——它提供概览和导航,让使用者快速找到需要的章节。SKILL.md 的 Quick Reference 表格就是这个导航。
reference/ = 知识库。企业知识库的特点是内容丰富但使用频率低,按需查阅而非每次通读。Skill 的 reference 文件同理——只有 Claude 判断需要时才加载。
templates/ = 标准化输出。企业用模板确保报告、邮件、文档的格式一致。Skill 的模板同理——Claude 不需要每次都“创造”一个报告格式。
scripts/ = 自动化工具。企业用脚本和工具自动化重复性操作。这里的关键洞察是,脚本把“知识”变成了“行动“——它是 Skills(知识层)和 Tools(行动层)的桥梁。
这引出了一个重要话题:Skills 和 Tools 到底是什么关系?它们如何协作?下面继续探讨。
Skills 与 Tools 的本质关系
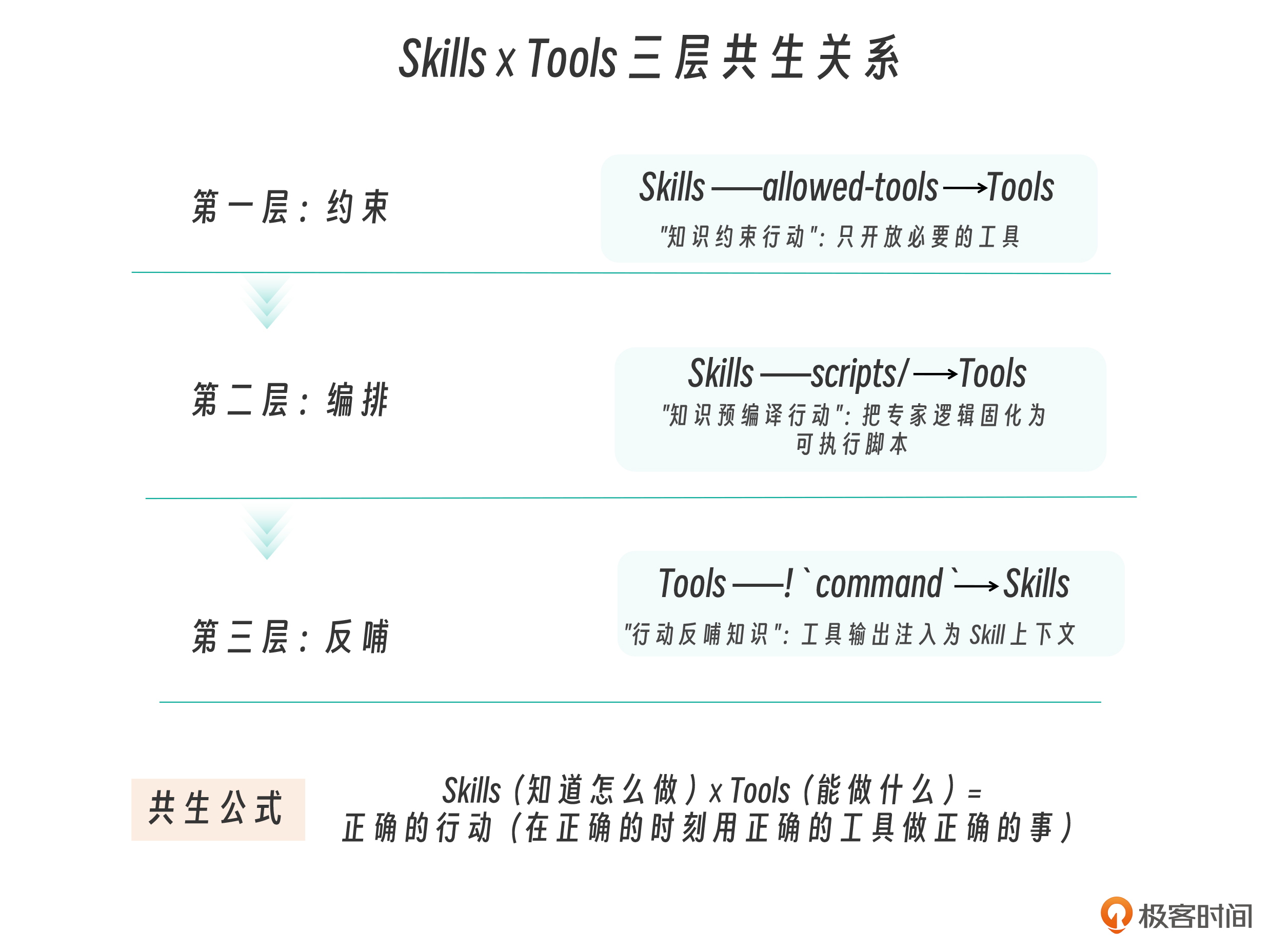
在第 9 讲对Skill进行定义的环节中,我们曾初步区分了 Skills(“经验”)和 Tools(“手”)。现在,让我们深入分析它们之间的三种协作模式。
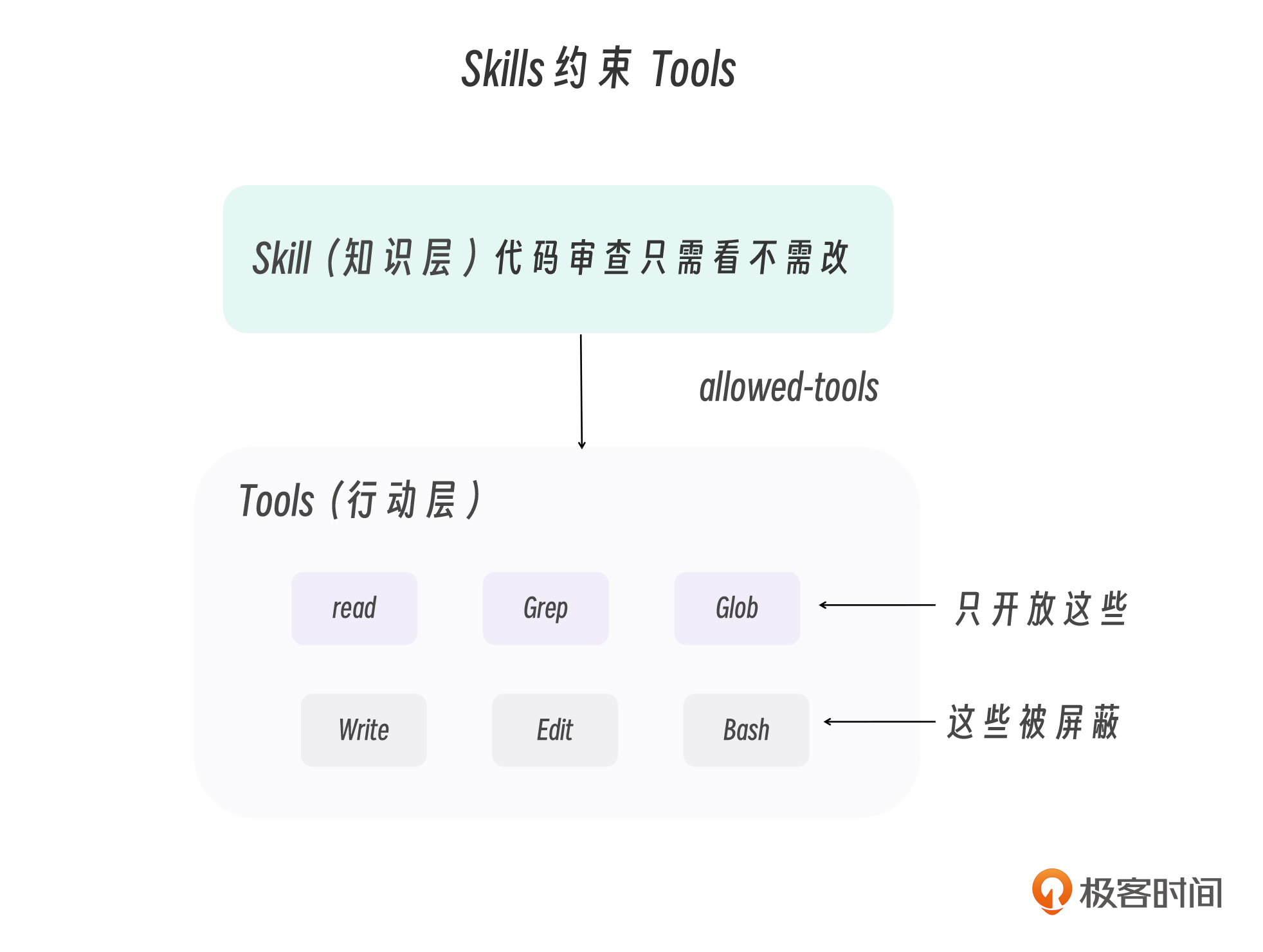
第一层关系是Skills 约束 Tools,Skills 通过 allowed-tools 约束 Tools,实现最小权限原则。
allowed-tools: - Read # 允许读取 - Grep # 允许搜索 - Glob # 允许查找 # 没有 Write、Edit、Bash → 不允许修改
这不是简单的权限控制——这是知识约束行动的范式。一个代码审查 Skill “知道”审查只需要看代码不需要改代码,所以它只给 Claude 只读工具。一个文档生成 Skill “知道”需要创建新文件但不应修改旧文件,所以它给 Write 但不给 Edit。
第二层关系是Skills 编排 Tools。Skill 中的 scripts/ 目录存放的脚本,本质上是预编译的 Tool 调用序列。
scripts/calculate_ratios.py
这个脚本 = Read(data_file) + 计算逻辑 + Print(results)
Claude 不需要理解计算逻辑,只需要:
1. Bash("python scripts/calculate_ratios.py data.json")
2. 读取输出结果
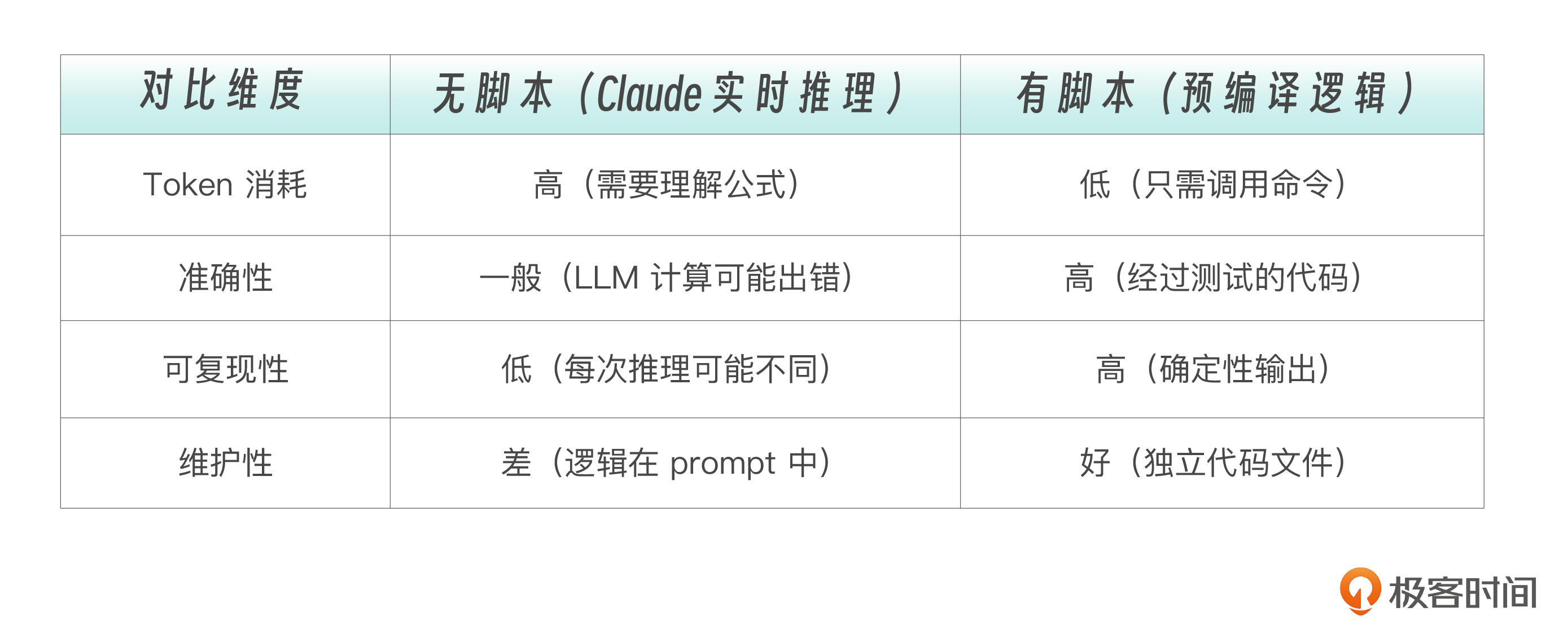
没有脚本时,Claude 需要自己组合多个 Tool 调用来完成任务:
手动编排(没有脚本): 1. Read(data.json) → 获取数据 2. Claude 内部计算 → 消耗推理 token 3. 可能出错 → 需要多轮修正
有脚本时,Claude 只需一次 Tool 调用:
脚本编排(有脚本): 1. Bash(python calculate.py data.json) → 直接获得结果
脚本是“预编译”的知识——它把人类专家的领域逻辑固化为代码,让 Claude 不需要在运行时“重新发明轮子”。
第三层关系是Tools 反哺 Skills。第 10 讲介绍的!command`` 语法展示了反向关系——Tools 的输出反哺 Skills 的上下文:
name: pr-summary description: Summarize changes in a pull request
Context
- PR diff: !
gh pr diff# Tool 输出 → 注入 Skill 上下文 - Changed files: !
git diff --name-only
这是 Tools 反哺 Skills 的预处理模式:Shell 命令在 Skill 加载之前执行,输出直接注入 SKILL.md 内容,Claude 收到的是已经包含实时数据的知识。
把上述三层关系做个总结我们可以得到下面的 Skills × Tools 共生公式。

本讲小结
好的,本讲内容就到这里了。我希望你记住的要点就是渐进式披露是 Skills 的核心架构模式——按需加载,节省 tokens。它的三层架构是目录页(description)→ 章节(SKILL.md)→ 附录(引用文件)。而且辅助文件和.claude/skills/
SKILL.md 是路由器,通过Quick Reference 表格用最少 token 完成路由判断。引用文件的“契约式”写法,即契约式引用会告诉 Claude 何时加载、加载什么、得到什么。这里有一个 500 行法则,超过就该重构——把参考、模板、示例移到辅助文件。通过脚本封装来封装确定性逻辑,Claude 执行但不需要理解脚本中的内容。
课程学到这里,我们已经掌握了两种上下文管理策略,分别是Skill的渐进式披露(按需加载)+ 子代理隔离(纯净上下文)。它们互相补充,解决不同的问题。我最后给出两种上下文管理策略表的对比。

组合使用:一个子代理可以通过 skills 字段预加载 Skill,而该 Skill 内部仍然用渐进式披露组织内容。两种策略是互补的。
如果你现在还没写过复杂 Skill,这一讲不要求你一次吃透,先记住三个词:目录、路由、契约。等你真正写过一个“知识+模板+脚本+数据”的 Skill,再回头看这三个词,会像突然点亮地图一样。
思考题
如果你的 Skill 有 20 个参考文件,你会如何组织,才能让 Claude 快速找到需要的内容?
什么样的内容应该放在 SKILL.md 主文件,什么样的应该放在引用文件?
渐进式披露和我们之前学的子代理“隔离上下文”有什么相似之处?
你有一个 Skill 的 SKILL.md 现在是 800 行,包含:100 行核心指令、200 行 API 规范、300 行代码示例、200 行错误处理模板。用拆分决策树重构它——画出重构后的目录结构,写出 SKILL.md 中对每个文件的“契约式引用”。
设计一个“可视化输出”类型的 Skill:选择你项目中的一个分析需求(测试覆盖率/依赖关系/API 调用链),设计 SKILL.md + scripts/ 的目录结构,说明 Claude 只需要知道什么(最少 token),脚本负责什么(最多逻辑)。
用“认知经济学”分析你项目中一个现有 Skill(或设计一个新的):画出 token 投入 vs 任务完成质量的曲线。哪些知识是关键知识(高边际收益)?哪些是冗余知识(接近零收益)?如何通过渐进式披露把 ROI 最大化?
分析 Skills × Tools 的三层关系在你项目中的应用:你的 Skill 需要约束哪些 Tools?有哪些确定性逻辑适合封装为脚本(预编译知识)?有哪些实时数据适合用 !command`` 预加载(Tools 反哺)?你可以自己设计出你的 Skills × Tools 协作图。
下一讲预告
我们已经掌握了 Skills 的结构和渐进式披露架构。下一讲,我们将学习Skills 与 SubAgent 的配合实战,通过递进式的项目设计(API 生成器 Skill + SubAgent 配合),掌握 Skills 的高级组件架构和 SubAgent 配合执行的各种模式。
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,别忘了分享给身边更多朋友。